Retrieval-Augmented Image Synthesis: A Researcher's Guide
[1029 words, 4-minute read]
Retrieval-Augmented Image Synthesis (RA-IS) first retrieves relevant images from a database and then generates the image grounding in the retrieved images. RA-IS has been shown to (1) enhance image quality; (2) guide image styles; and (3) help faithfully generate specific objects (e.g., The Oriental Pearl Tower). Fig 1 and 2 show some examples. This article explains the overall architecture of RA-IS with a focus on diffusion-based models, providing a getting-started guide for researchers who are familiar with image synthesis models but new to RA-IS.


Retrieval-Augmentation for auto-regressive and diffusion models
Two types of image synthesis architectures have been used in RA-IS: Autoregressive (AR) and Latent Diffusion models (LDM).
The auto-regressive approach converts image synthesis to a sequence generation problem. In these models, images are represented as a sequence of image tokens from a learned codebook. A Transformer is typically trained to generate the image-token sequence. The Causal Masked Multimodal Model (CM3) [1] belongs to this category. Augmenting AR model with retrieval is easy: you simply provide the retrieved text-image pairs as the model's input, just as providing in-context examples to a language model.
LDM uses the denoising process to synthesize images from noises. A UNet predicts the noises to be removed in the reverse process and eventually recover the image. Input prompts control the generation process via the cross-attention blocks in the UNet. Current Retrieval-Augmented LDM conditions the generation with the retrieved images similarly: feeding the CLIP embeddings as inputs to the UNet's cross-attentions. The Retrieval-Augmented Diffusion Model (RDM) [3, 4] adopts such architecture.
In the next section, we introduce the architecture of RDM in more detail as the formulation accommodates both auto-regressive and diffusion-based approaches.
The Retrieval-Augmented Diffusion Model
RDM is introduced in [4]. During training, the model retrieves \(k\) neighbors from a database \(D_{train}\) and learns to generate the target image given the CLIP embeddings of the retrieved neighbors. The retrieval strategy during training is denoted as \(\epsilon_k^{train}\). During inference, an alternative database may be used, and the retrieval strategy may vary. The number of neighbors to retrieve, \(k\), is a fixed hyper-parameter shared in training and inference.
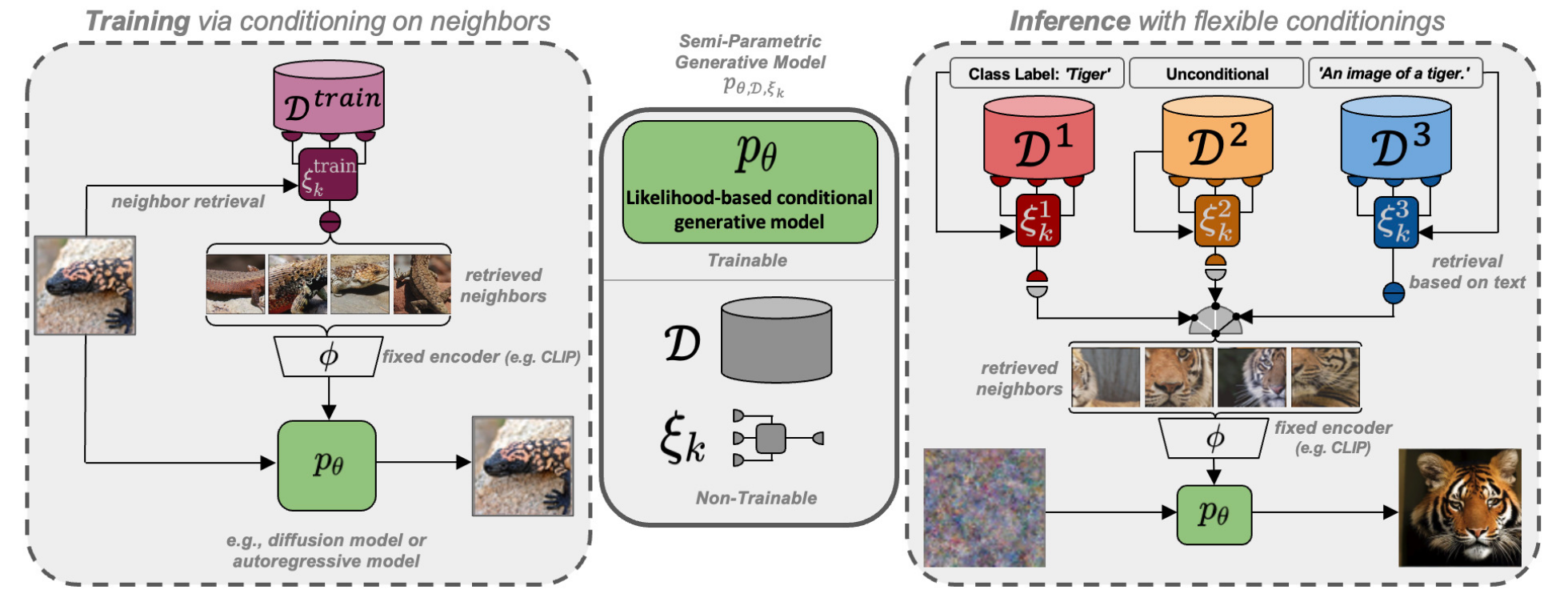
RDM can perform:
- Image-Grounded Generation: retrieve \(k\) images and perform inference similar to the forward process in training.
- Text-to-Image Generation: use the CLIP embeddings of text prompts (e.g., "An image of a tiger") only to condition the generation process. This is possible because CLIP text and image embeddings are in the same space.
- Unconditional Generation: retrieve \(k\) images from \(D_{train}\) based on a pseudo-query to condition the generation process. The pseudo-query is sampled from a proposal distribution based on the retrieval dataset \(D\).
The authors train and evaluate RDM on ImageNet using FID as the metric. They find that:
- A larger training database \(D_{train}\) improves performance: They use WikiArt (138K), MS-COCO (328K), and OpenImages (20M) and retrieve from the same dataset during inference. At epoch 50, RDM-OpenImages achieves ~20 FID whereas RDM-COCO and RDM-WikiArt achieves ~35 and ~45, respectively.
- Class-condition generation is possible without specific training by retrieving examples using the prompt “An image of a [class]”.
- Zero-shot stylization by exchanging the inference dataset. By changing the retrieval database during inference, RDM can follow the style of the database without additional training (Fig. 4) [3].

In summary, [3,4] show empirically that retrieval augmentation can substantially enhance image quality, change generation style, and perform class-condition generation. We now turn to future directions of the field.
Future Directions
- Alternative design to condition diffusion model with retrieved images. There is a large design space for how the diffusion process can be conditioned given the retrieved images. RE-IMAGEN [2] provides a similar approach to RDM (Fig. 5). In their work, fewer neighbors are used (\(k=2\)).
- Better retriever. [2,3,4] uses BM25, a basic text-based sparse retriever, to retrieve relevant images. SOTA vision-language retrievers such as FLMR may be trained to more accurately retrieve relevant images.
References
- [1] M. Yasunaga et al., “Retrieval-Augmented Multimodal Language Modeling.” arXiv, Jun. 05, 2023. doi: 10.48550/arXiv.2211.12561.
- [2] W. Chen, H. Hu, C. Saharia, and W. W. Cohen, “Re-Imagen: Retrieval-Augmented Text-to-Image Generator,” presented at the The Eleventh International Conference on Learning Representations, Sep. 2022. Accessed: Jan. 14, 2024. [Online]. Available: https://openreview.net/forum?id=XSEBx0iSjFQ
- [3] R. Rombach, A. Blattmann, and B. Ommer, “Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models.” arXiv, Jul. 26, 2022. doi: 10.48550/arXiv.2207.13038.
- [4] A. Blattmann, R. Rombach, K. Oktay, J. Müller, and B. Ommer, “Semi-Parametric Neural Image Synthesis.” arXiv, Oct. 24, 2022. doi: 10.48550/arXiv.2204.11824.
Comments ()