Telling AI from Human: DeepFake Texts in the era of Large Language Models. Tutorial Notes @NAACL 2024

This blog is NOT written or revised by AI.
Human can be held responsible for what they write, whereas AI cannot. With capable language models such as ChatGPT, writing irresponsibly has become easier than ever. In the NAACL 2024 Tutorial by Adaku Uchendu et al. titled Catch Me if You GPT, Professor Dongwon Lee shows how effortless it is to generate fake news with readily available AI tools: prompt ChatGPT for text, generate image with Midjourney, attach big-name logo, and there you go:

This blog provides a 5-minute high-level summary of the 3-hour tutorial, covering three core topics concerning DeepFake texts: watermarking, detection, and obfuscation.
Watermarking: towards responsible LLM provider
Watermarks have been widely used in protecting image authorship. They are mostly small icons in the corner which declares ownership while incurring minimal change to the image. As a language model provider, "watermarking" model's text output can claim authorship and signal its AI-generated nature.

Watermarking texts is much less straightforward than image. In NLP, watermarking refers to instilling patterns in the generated texts which is indiscernable to human but decipherable by machines to carry meta-information. There are mainly two approaches: post-generation watermarking and in-generation watermarking.
Post-generation watermarking establishes a hidden pattern by tweaking generated texts in semantically equivalent ways. For example, changing from American spelling to British spelling ("favorite" -> "favourite") or using synonyms. Done systematically, this can encode meta-information in the modified text.
In-generation watermarking, or LLM watermarking in the tutorial, refers to modifying the LLM generation procedure (decoding) to instill patterns. One of the most cited methods, the KGW algorithm, modifies generation at the logits-level. In generating each token, KGW first divides the vocabulary into two groups, a watermark group (Green) and a non-watermark group (Red), randomly with respect to a random seed produced by a hash function. Then, KGW reweighs the logits to make a valid output distribution and generates token from the watermark group. As a result, the generated text will contain a lot of green-list tokens, which is very unlikely without watermarking. This is how a detector can tell if the text is machine-generated.
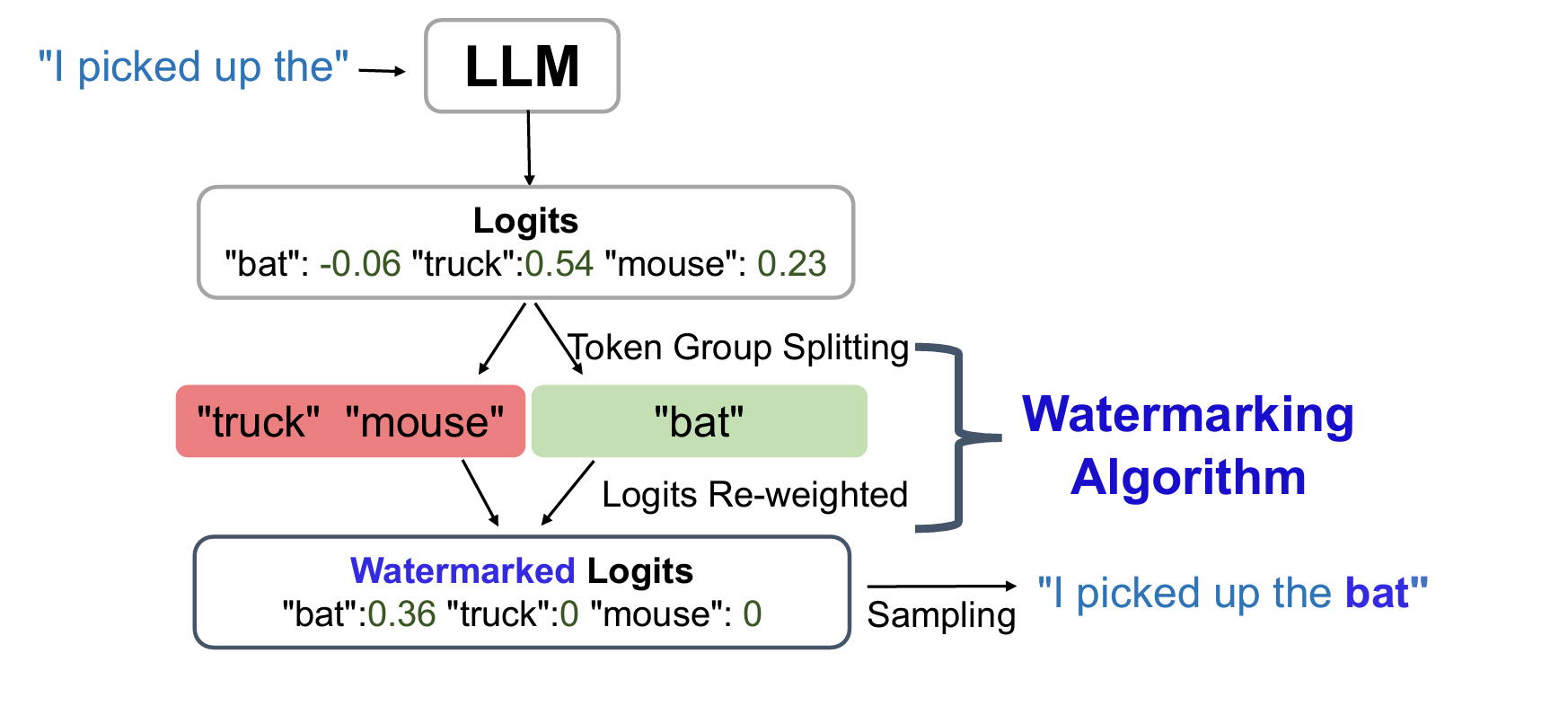

The KGW algorithm is "zero-bit" watermarking, as it only indicates whether the text is machine-generated or not. Subsequent efforts encode multiple bits by spliting logits into more groups (paper), or divide many completed generated candidates into groups based on their embeddings (paper).
Detection
Detecting AI-generated texts without watermarks is difficult. Individual human experts only succeed 56% of the time on average, with non-experts at a worse-than-random 45%.
Stylometric-based detection was the focus of early research. These detectors make use of linguistic features, Linguistic Inquiry and Word Count (LIWC) and Readability, etc., to classify machine/human-written texts. However, they struggle at identifying more recent models such as ChatGPT, which can be asked to change writing sytles via prompting.
Deep-learning classification models prove to be very strong baselines, with fine-tuned BERT-based classifier attaining overall >85% accuracy, beating many statistical approaches that mine for linguistic patterns such as word use and styles. Deep-learning classifier if the de facto approach in AI text detection. Adam Alex, presentor from the commericial AI detection tool provider GPTZero, shared that the company main technology stack has indeed evolved into deep-learning from early statistical approaches based on perplexity and burstiness.
Prompt-based approaches, using LLM themselves to tell AI from human via prompting, have been (surprisingly) unfruitful, with GPT-4 scoring 38% in distinguishing ChatGPT's generations (Figthing fire with fire). Hybrid approaches that combine feature mining with deep-learning has seen more success (TDA-based detector). Human-based approaches generally struggle at near-random performance, but can be improved if human evalutors collaborate. Human experts collaborating face-to-face scores 69% in accuracy compared to 56% without collaboration.
Obfuscation
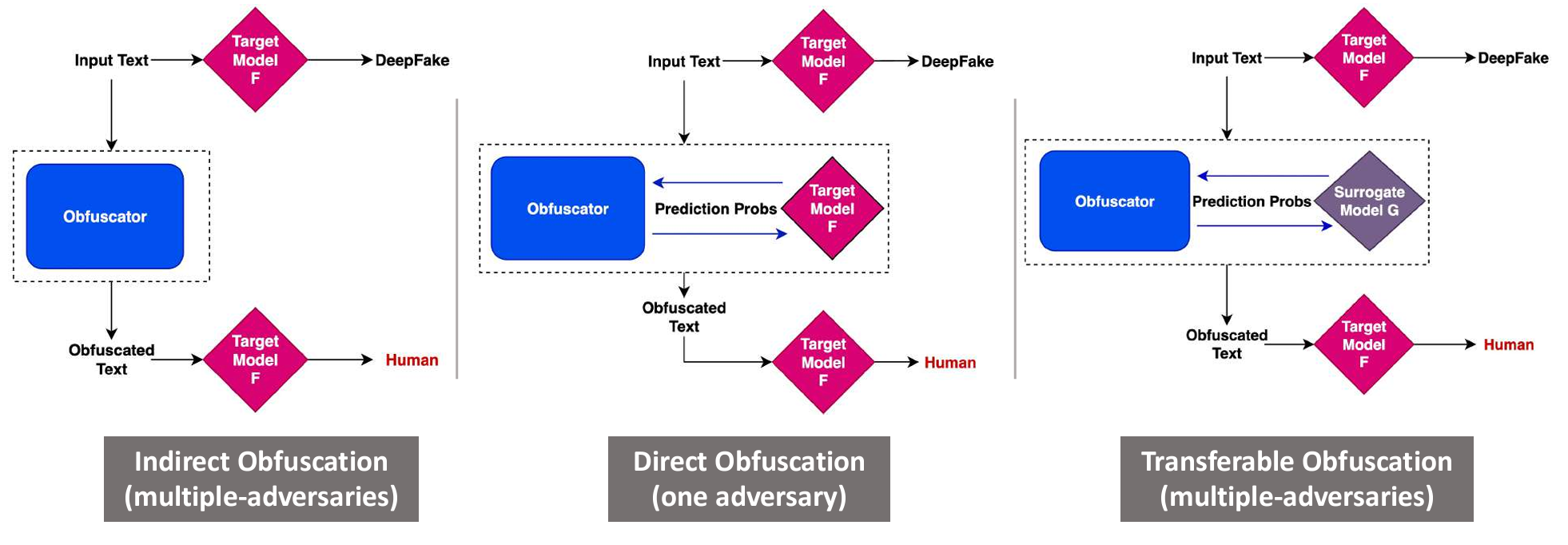
Obfuscation aims to make AI-generated texts undetectable. It is adversarial to the detector. There are three main scenarios (or "threat models") of obfuscation: Indirect Obfucation is when the obfuscator requires no access to the detector nor the target model. Direct Obfuscation assumes access to the target model, modifying texts in order to fool the particular detector. Transferable Obfuscation refers to the case where there is no access to the target model/detector, but surrogate models are available.
In terms of approaches, Stylelometric Obfuscation has been studied since 2016, with the early PAN tasks developing approaches such as applying text transformation (remove stopwords, insert punctuation, lower case) and back-translation (e.g., English->German->English). The idea is that these transformations could hide the stylelometric characteristics of machine-generated texts. More recent approach utiilizes pre-trained LLM to replace most confident predicted words with lower confident synonyms.
Statistical Obfuscation generally uses an internal deepfake detector and uses its signal to guide token generation or decoding procedure such as beam search. It is found that misalignment in decoding procedure between the generator and the detector can reduce performance by 13.3% to 97.6% (paper). It is not surprising as classical watermarking and detection approaches make heavy use of the model's logits and a different decoding strategy can make substantial change to them during text generation.
Conclusion
Being able to tell AI from human is important for maintaining trust in written texts. Watermarking, detection, and obfuscation have emerged as three important topics for today's AI security research. The methodology is predominately deep-learning in commercial tools like GPTZero and in the research community.
Having worked closely with text and image generation model in my PhD, I have developed a sense f0r machine-generated content (yes, I won first place in the identify-deepfake quiz). From my experience, the text quality from GPT-4 is by far worse than capable human writers, and can be easily distinguishable from stylistic human writing. But I see distinguishing GPT-4 from average human writer more of a context-dependent ethnical challenge than a technological one. As models continue to improve, this will become increasingly difficult, if not impossible. It is indeed as Prof. Lee said towards the end of the tutorial, calling for more attention to the factuality of AI-generated content rather than identity: "Most of the times, I don't care whether it is AI-written or not. I care about whether it is the truth".
Read about my other articles: https://www.jinghong-chen.net/tag/articles/ and my works https://www.jinghong-chen.net/tag/my-work/
Comments ()