PreFLMR: SoTA Open-sourced Multi-modal Knowledge Retriever from Scaling Up FLMR
[1,087 words, 5-minute read]
Three products emerged from our study in scaling up multi-modal late-interaction retrievers:
- The Multi-task Multi-modal Knowledge Retrieval benchmark (M2KR) totaling 4.4M training examples for training and comprehensively evaluating knowledge retrievers on question-to-doc, image-to-doc, and question+image-to-doc tasks.
- The Pretrained Fine-grained Late-interaction Multi-modal Retriever (PreFLMR) which enhances the FLMR model by scaling up model parameters and data, yielding the state-of-the-art retriever on 7 out of 9 tasks in M2KR at the time of publication. We open-source model weights along with HuggingFace compatible hit-to-run implementation here.
- The first systematic investigation of scaling up late-interaction retrievers which, as we showed in this NeurIPS paper, surpasses Dense Passage Retreiver (DPR) by large margins in multi-modal knowledge retrieval. We compare the effectiveness of scaling up individual model components, shedding light on where to increase parameters.
All open-sourced artifacts can be found here: https://preflmr.github.io/. This post provides a concise overview of our methods and contributions.
The M2KR Benchmark
Before M2KR, there was no dedicated dataset for training multi-modal knowledge retriever in the order of millions. To enable large-scale pretraining and comprehensive evaluation, we compiled 9 existing datasets originally intended for tasks such as image captioning and multi-modal conversations into a uniform retrieval format. This yields a >4 million diverse collection encompassing image-to-document, question-to-document, and image+question-to-document tasks.
Figure 1 shows some example questions and corresponding ground-truth documents from M2KR.

PreFLMR
PreFLMR is the Fine-grained Late-interaction Multi-modal Retriever (FLMR) pretrained on the M2KR benchmark and with some modeling improvements. Compared to the widely used Dense Passage Retrieval (DPR)which uses one vector to embed query/document and dot product to obtain relevance score, FLMR represents query/document as a matrix of token embeddings and compute relevance score via 'late-interaction', an efficient algorithm to aggregate all token-level relevance. Figure 2 shows the PreFLMR architecture. See my other post for the FLMR architecture and our experiment results showing FLMR's superior performance over DPR.
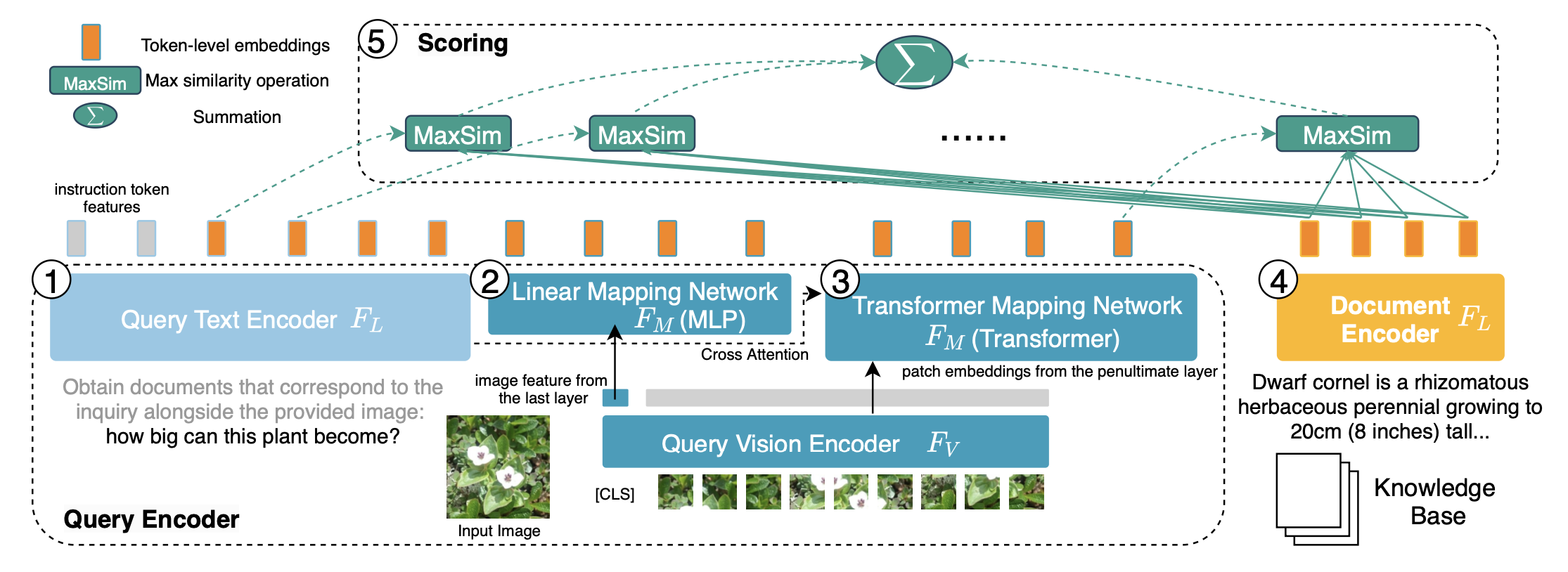
In terms of modeling, PreFLMR improves over FLMR in three aspects: (1) while FLMR only uses the [CLS] embedding from ViT as the image representation, we additional extract the image patch embeddings from ViT's penultimate layer to enrich visual representation; (2) we introduce a text-image cross-attention block in mapping image embedding to the language model embedding space. This allows us to extract the visual features most relevant to the text query; (3) we use task-specific instructions to guide PreFLMR to perform different types of retrieval tasks (See Figure 1 for example instruction).
PreFLMR training involves four stages:
- Stage 0: we train ColBERT on MSMARCO to obtain the initial checkpoint for PreFLMR's text encoder.
- Stage 1: we only train the mapping structure on all three type of tasks in M2KR. At this stage, we only use the mapped visual representations to perform retrieval, masking out embeddings from the text encoder. This prevents the model from soly relying on the text query representation.
- Stage 2: we tune the text encoder and the mapping structure on the E-VQA dataset, a large and high-quality Knowledge-Based VQA dataset. This intermediate pretraining stage improves PreFLMR capability as a multi-modal knowledge retriever with in-domain data.
- Stage 3: we fine-tune on the entire M2KR corpora, only freezing the vision encoder. Additionally, we use separate text encoders to encode queries and documents; their parameters were shared in previous steps.
We also show that PreFLMR can be further fine-tuned on down-stream task (e.g., OK-VQA) for better retrieval performance on that task.
Results and Scaling Behavior
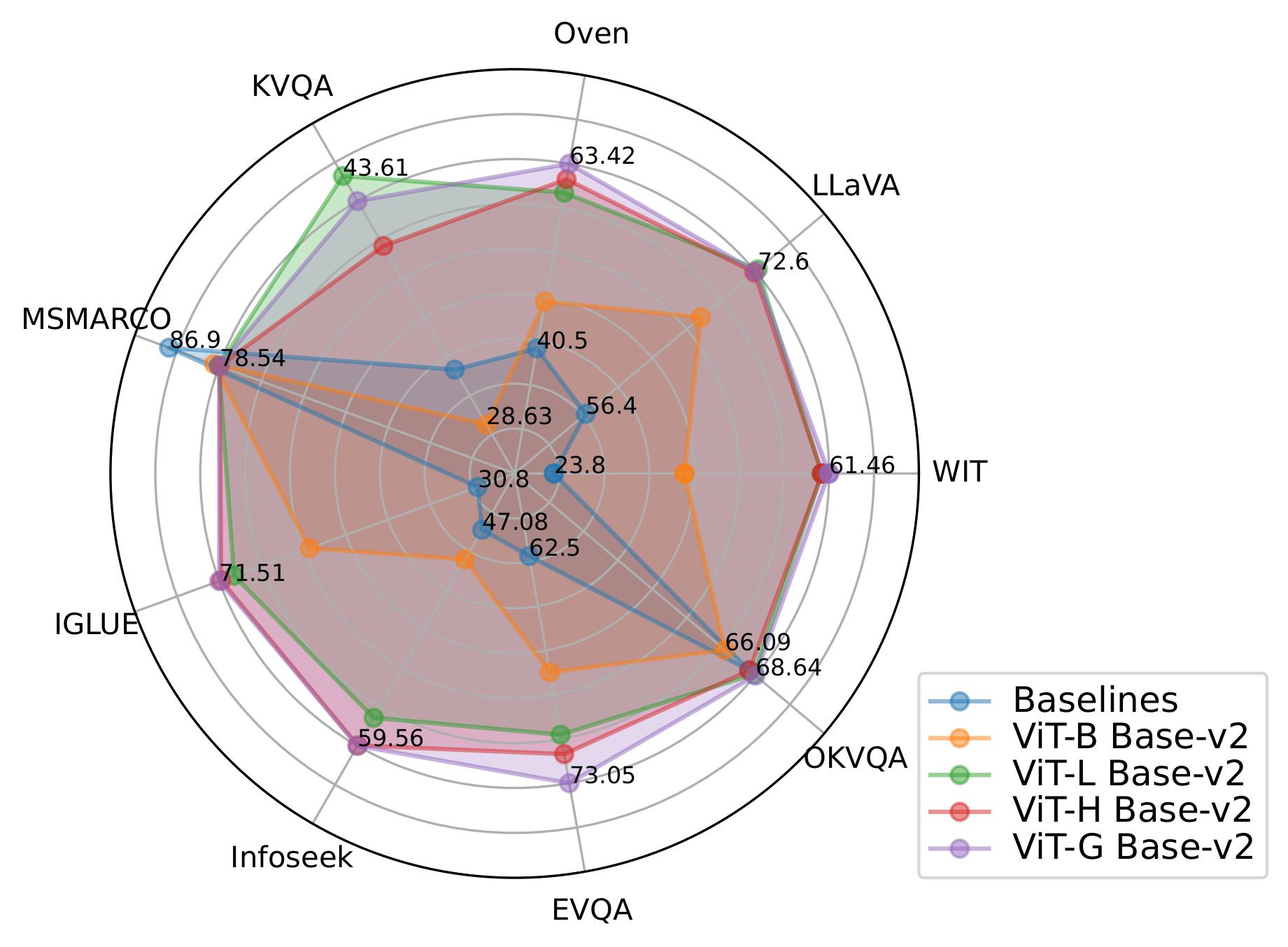
Main Results. Our best performing PreFLMR variant achieves SOTA results on 7 out of 9 retrieval tasks in M2KR. It has 2B parameters in total, using ViT-G as the visual encoder and ColBERT-base-v2 as the text encoder.
Scaling Vision over Text. We find that scaling up ViT from ViT-B (86M) to ViT-L (307M) yields substantial gain across all tasks, whereas upgrading the ColBERT model from base (110M) to large (345M) harms performance and leads to unstable training. This suggests that scaling up the vision encoder (Figure 3) is more effective and practical than using a larger text encoder in building multi-modal late-interaction retriever. Using more cross-attention layers in the mapping structure affects performance marginally and we stick to the 1-layer design.
Intermediate pretraining is effective. Although intermediate training is conducted on the E-VQA dataset only, the scores on other KB-VQA datasets (Infoseek, KVQA, OKVQA) increase by ~1% or more. We hypothesize that this is because E-VQA captures characterisitics mutual to KB-VQA tasks and quantatively measures the gain with difference in minimal validation loss achieved with or without intermediate pretraining. This measure is backed by a tentative theory for quantifying "mutual information" between datasets which we put forward based on V-Entropy in the paper.
PreFLMR boosts KBVQA with RAG. We also show that PreFLMR can boost performance on challenging KB-VQA tasks via Retrieval-Augmented Generation (RAG). Our RAG system with PreFLMR retriever and BLIP-2 generator brings about 94% and 275% performance gain on Infoseek and E-VQA compared to without RAG, respectively, beating much larger previous SOTA (PALI-X and PaLM-B+Lens) models.
Conclusion
My wonderful co-authors, Weizhe Lin and Jingbiao Mei (Howard), have made great effort in making an easy-to-use HuggingFace-style implementaion. So look no further for a usable SOTA multi-modal retriever for your research or projects! All resources can be found in the project page.
This project is the product of a two-month sprint on the AWS using Amazon research grants at the University of Cambridge.

Comments ()