Catch up on Speculative Decoding in 5 minutes: a survey for researchers as of December 2023
Speculative decoding speeds up LLM inference without any loss of generation quality. As of December 2023, researchers have reported ~2x speed-up from applying speculative decoding to 3B to 1T models. This survey explains the latest speculative decoding methods that enable lossless speed-up, examines reported experimental results, and suggests future research directions based on my reading of 7 papers. References at bottom.
The Basis: Speculative Sampling
In this survey, "speculative decoding" is a family of lossless LLM inference methods based on the following procedure known as speculative sampling:
- Draft: a small model (draft model, \(p(\cdot|\text{context})\)) quickly generates a K-token draft.
- Verify: the big LLM (target model, \(q(\cdot|\text{context}+\text{draft})\)) evaluates the draft with one forward pass.
- Accept/Resample: Decide the longest prefix in the draft to accept and sample a token from an adjusted distribution, \(\text{normalize}(\max(0, q(x)-p(x)))\), to replace the first rejected token. Repeat.
Generating from the draft model (usually 10x smaller) has negligible cost compared to running the target model. Suppose \(\gamma\) tokens are accepted in a cycle, the target model is only invoked once in the verify step, whereas in regular decoding \(\gamma\) forward passes are needed. This is the source of speed-up.
Speculative sampling is proposed by two concurrent works by Google [1] and DeepMind [2] in 2023. Their proposed accept/resample scheme ensures that the sampled tokens follow the target model's distribution \(q\). See proof in [1] and an intuitive derivation here. Their draft models are smaller variants of the target model. Subsequent works mainly explore alternative designs of the draft model.
Three Types of Draft Models
Draft models fall into three categories: stand-alone models, decoder heads, and pruned models.
Stand-alone models. In Google's work [1], a T5-SMALL (77M) drafts for a T5-XXL (11B). In DeepMind's work [2], a 4B Chinchilla drafts for a 70B Chinchilla. Stand-alone draft models are trained on a target corpus (e.g., WMT En->De) or on the target model's generated text (sequence-level distillation).
Decoder heads are extensions of the target model to generate drafts. The \(K^{\text{th}}\) decoder head uses the target model's activation to predict the \({K+1}^{\text{th}}\) token into the future in parallel to other decoder heads. This non-autoregressive drafting scheme, inspired by Blockwise Parallel Decoding [7] proposed in 2018, combines the draft stage and the verify stage. Medusa [4] trains such decoder heads for a Vicuna.
Pruned models are "pruned" versions of the target model for drafting. In Self-Speculative Decoding, 40 layers in the Llama-2-13B model are skipped for fast drafting. They use Bayesian Optimization to select layers to skip, explicitly optimizing the inference speed per token.
Cool. But how good are they and on what tasks are they evaluated? Let's take a closer look at the experimental results from the papers.
Experimental Results from Papers
Table 1 summarizes recent speculative decoding systems. They are evaluated on Machine Translation (WMT), Summarization (XSum, CNN/DM), Code Generation (HumanEval), and Prompts from Human (LM1B, MTBench). Overall, speculative decoding doubles the inference speed compared to regular decoding.
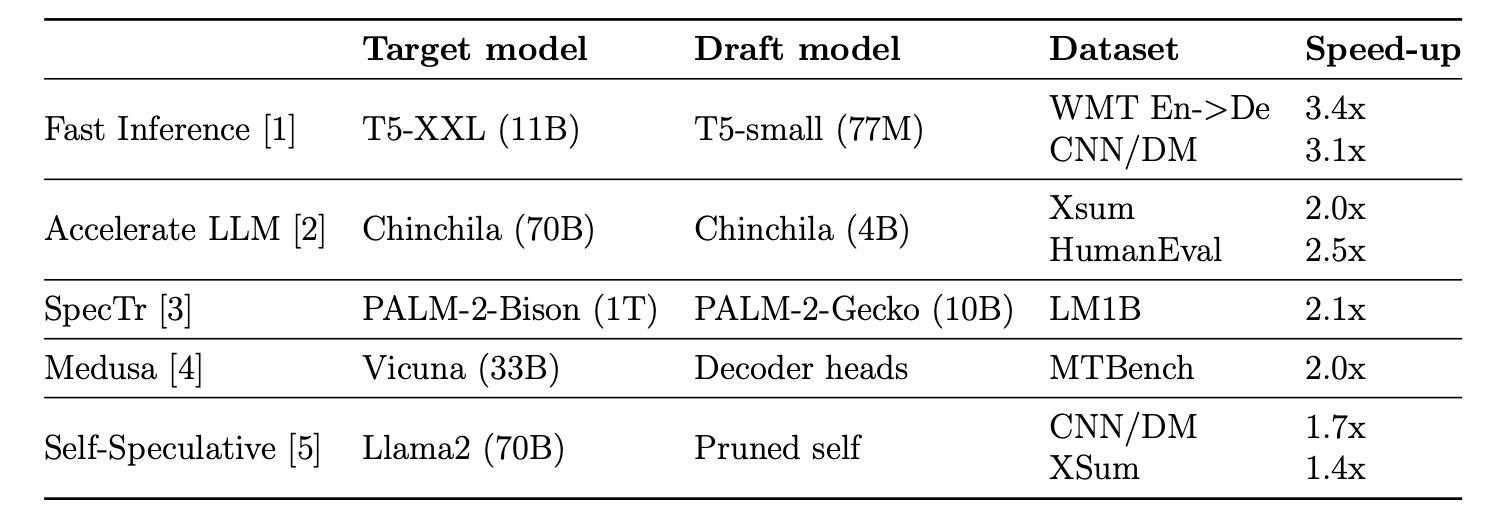
Let's scrutinize these numbers. In my view, the speed-up reported in [1] is too optimistic. The target model and the draft model are fine-tuned on the same corpus (WMT or CNN/DM) and evaluated on respective validation sets. This aligns the output distribution of the draft and the target model and does not evaluate samples that are out of distribution for the draft model. In real applications, the target and the draft distributions have large divergence and the draft model sees challenging inputs beyond its capabilities much more frequently.
DeepMind [2] trains a 4B Chinchilla using the same hardware and datasets as Chinchilla. Google's SpecTr [3] uses a 10B PALM to draft for a 1T PALM. Both reported 2-2.5x speed-up, which can serve as a performance baseline for speculative decoding approaches. Replication is out of the question though.
I think Medusa [4] gives the most instructive results. The MTBench is challenging, and training decoder heads on ShareGPT with open-sourced Vicuna only takes one day on an A100-80G. Self-Speculative [5] does not require any training, but the results are not as promising as others.
To summarize, current works show that speculative decoding can lead to 2x inference speed in principle. Still, few demonstrate such speed-up on challenging tasks with affordable computational resources.
Future Research Directions
Here are some active research questions for speculative decoding:
- Pushing for longer accepted draft per cycle. The analysis in [1] shows that the speed-up from speculative decoding is dominated by the accepted draft length per cycle. Currently, only 2-3 draft tokens are accepted per cycle on average, leading to a 2-3x speed-up. One solution is to build better draft models. Optimal Transport [3] has been used to formulate how well the draft approximates the target and online learning [6] has been applied to adjust the draft model on-the-fly.
- Demonstrate effectiveness in real-world settings. Medusa [4] has a reasonable setting. It would be good to show speculative decoding offers reliable speed-up when faced with more diverse queries and tasks.
This completes the survey.
Speeding up LLM inference is of great interest at the time of writing. I will write more on speculative decoding and am happy to discuss related ideas. Hope you enjoyed reading.
References
[1] Fast Inference from Transformers via Speculative Decoding. Paper.
[2] Accelerating Large Language Model Decoding with Speculative Sampling. Paper.
[3] SpecTr: Fast Speculative Decoding via Optimal Transport. Paper.
[4] Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads. Project page.
[5] Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. Paper.
[6] Online Speculative Decoding. Paper.
[7] Blockwise Parallel Decoding for Deep Autoregressive Models. Paper.
Comments ()